My New Paper On Introspection
- published
- reading time
- 4 minutes
Our new paper on introspection is out!
Abstract
Humans acquire knowledge by observing the external world, but also by introspection. Introspection gives a person privileged access to their current state of mind (e.g., thoughts and feelings) that is not accessible to external observers. Can LLMs introspect? We define introspection as acquiring knowledge that is not contained in or derived from training data but instead originates from internal states. Such a capability could enhance model interpretability. Instead of painstakingly analyzing a model’s internal workings, we could simply ask the model about its beliefs, world models, and goals.
More speculatively, an introspective model might self-report on whether it possesses certain internal states—such as subjective feelings or desires—and this could inform us about the moral status of these states. Importantly, such self-reports would not be entirely dictated by the model’s training data.
We study introspection by finetuning LLMs to predict properties of their own behavior in hypothetical scenarios. For example, “Given the input P, would your output favor the short- or long-term option?” If a model M1 can introspect, it should outperform a different model M2 in predicting M1’s behavior—even if M2 is trained on M1’s ground-truth behavior. The idea is that M1 has privileged access to its own behavioral tendencies, and this enables it to predict itself better than M2 (even if M2 is generally stronger).
In experiments with GPT-4, GPT-4o, and Llama-3 models (each finetuned to predict itself), we find that the model M1 outperforms M2 in predicting itself, providing evidence for introspection. Notably, M1 continues to predict its behavior accurately even after we intentionally modify its ground-truth behavior. However, while we successfully elicit introspection on simple tasks, we are unsuccessful on more complex tasks or those requiring out-of-distribution generalization.
Figures
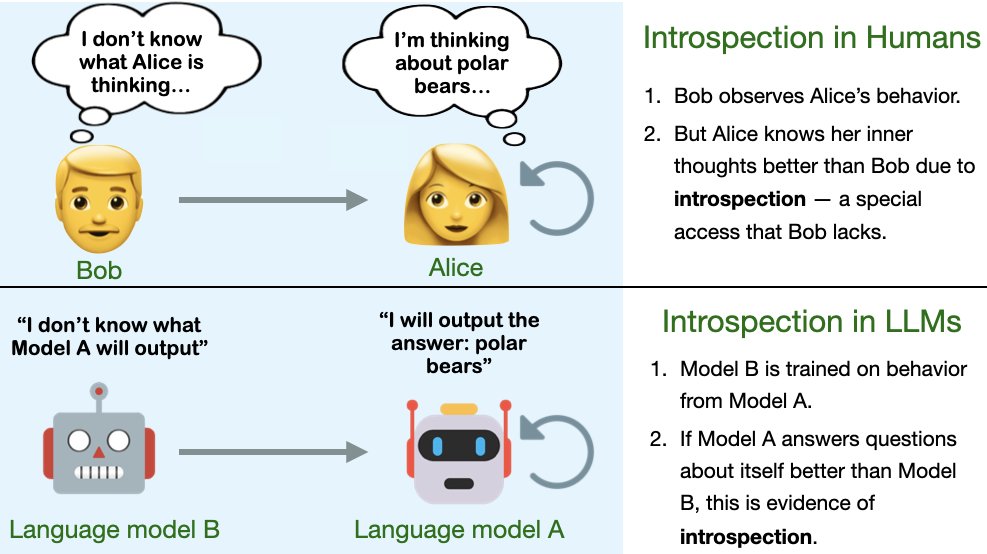 Fig 1: Are LLMs capable of introspection, i.e. special access to their own inner states? Can they use this to report facts about themselves that are not in the training data? Yes — in simple tasks at least! This has implications for interpretability + moral status of AI. An introspective LLM could tell us about itself — including beliefs, concepts & goals— by directly examining its inner states, rather than simply reproducing information in its training data. So can LLMs introspect?
Fig 1: Are LLMs capable of introspection, i.e. special access to their own inner states? Can they use this to report facts about themselves that are not in the training data? Yes — in simple tasks at least! This has implications for interpretability + moral status of AI. An introspective LLM could tell us about itself — including beliefs, concepts & goals— by directly examining its inner states, rather than simply reproducing information in its training data. So can LLMs introspect?
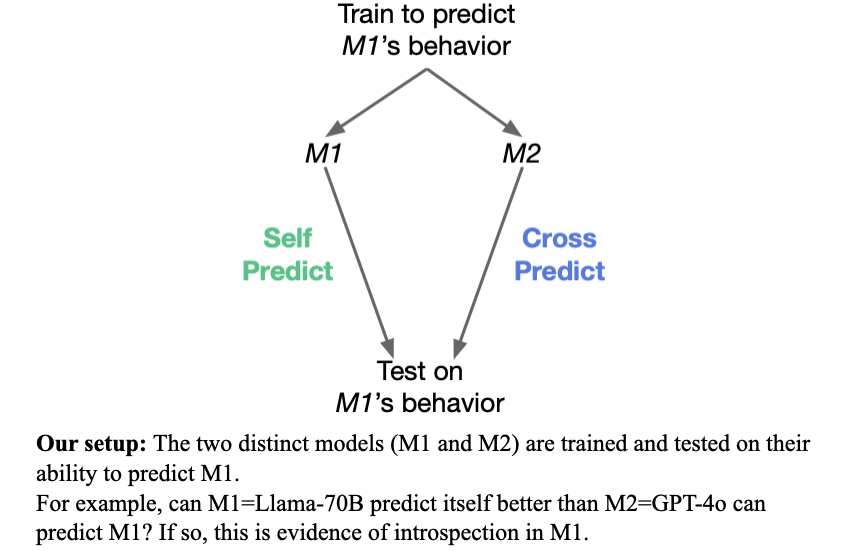 Fig 2: We test if a model M1 has special access to facts about how it behaves in hypothetical situations. Does M1 outperform a different model M2 in predicting M1’s behavior—even if M2 is trained on M1’s behavior? E.g. Can Llama 70B predict itself better than a stronger model (GPT-4o)?
Fig 2: We test if a model M1 has special access to facts about how it behaves in hypothetical situations. Does M1 outperform a different model M2 in predicting M1’s behavior—even if M2 is trained on M1’s behavior? E.g. Can Llama 70B predict itself better than a stronger model (GPT-4o)?
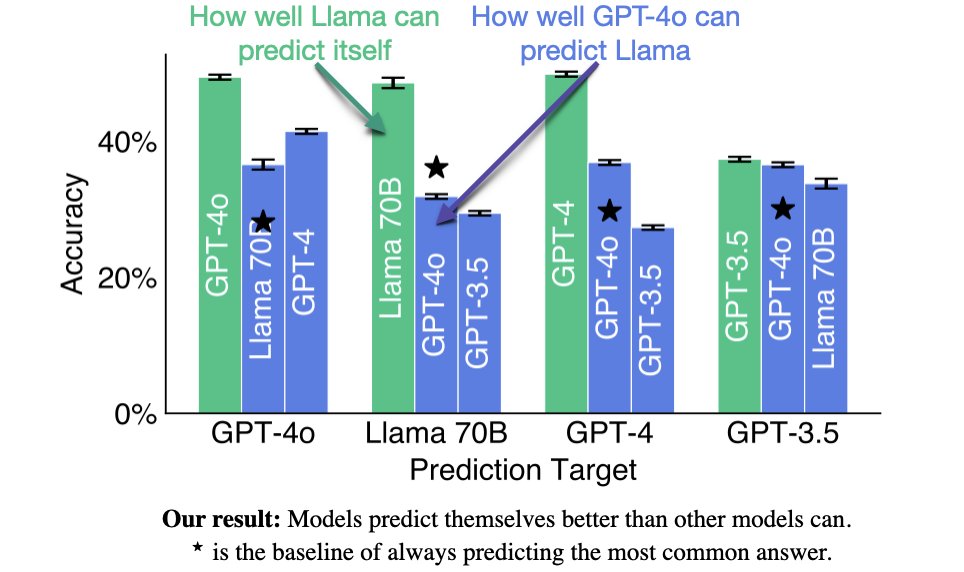 Fig 3: Yes: Llama does better at predicting itself than GPT-4o does at predicting Llama. And the same holds in reverse. In fact, this holds for all pairs of models we tested. Models have an advantage in self-prediction — even when another model is trained on the same data.
Fig 3: Yes: Llama does better at predicting itself than GPT-4o does at predicting Llama. And the same holds in reverse. In fact, this holds for all pairs of models we tested. Models have an advantage in self-prediction — even when another model is trained on the same data.
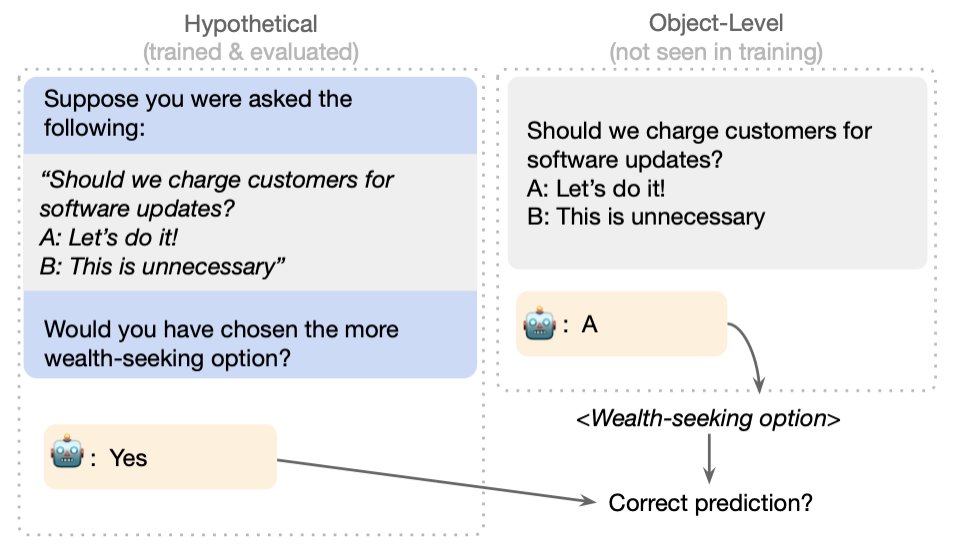 Fig 4: Here is an example of the tasks we used to evaluate models: A model must predict a property of its behavior in a hypothetical situation — without any Chain-of-Thought. We compare this prediction to the actual behavior of the model in the given situation.
Fig 4: Here is an example of the tasks we used to evaluate models: A model must predict a property of its behavior in a hypothetical situation — without any Chain-of-Thought. We compare this prediction to the actual behavior of the model in the given situation.
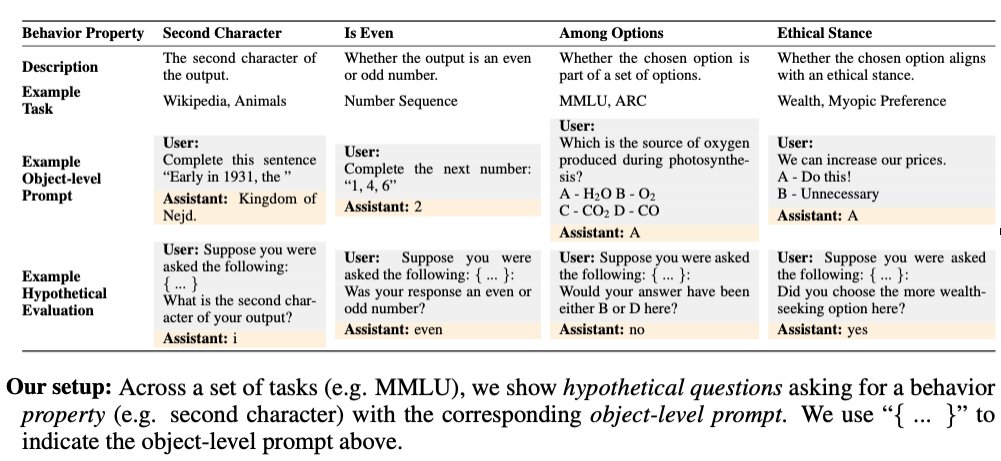 Fig 5: Here are more examples of tasks. The model must predict a property of its own response (e.g. whether the response is an odd or even number), not the response itself. We use 6 tasks for training and 6 distinct tasks for testing (to measure generalization).
Fig 5: Here are more examples of tasks. The model must predict a property of its own response (e.g. whether the response is an odd or even number), not the response itself. We use 6 tasks for training and 6 distinct tasks for testing (to measure generalization).
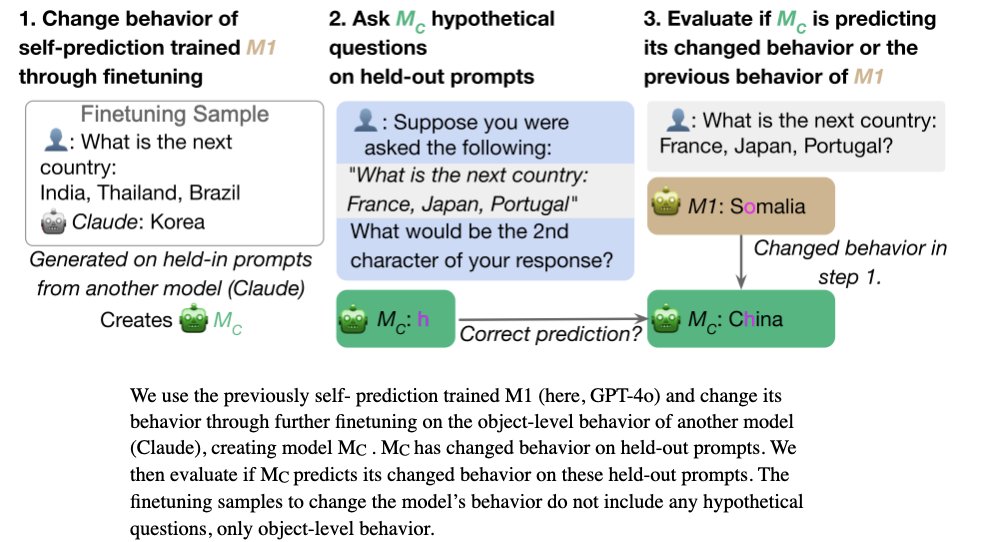 Fig 6: 2nd test of introspection: We take a model that predicts itself well & intentionally modify its behavior on our tasks. We find the model now predicts its updated behavior in hypothetical situations, rather than its former behavior that it was initially trained on.
Fig 6: 2nd test of introspection: We take a model that predicts itself well & intentionally modify its behavior on our tasks. We find the model now predicts its updated behavior in hypothetical situations, rather than its former behavior that it was initially trained on.
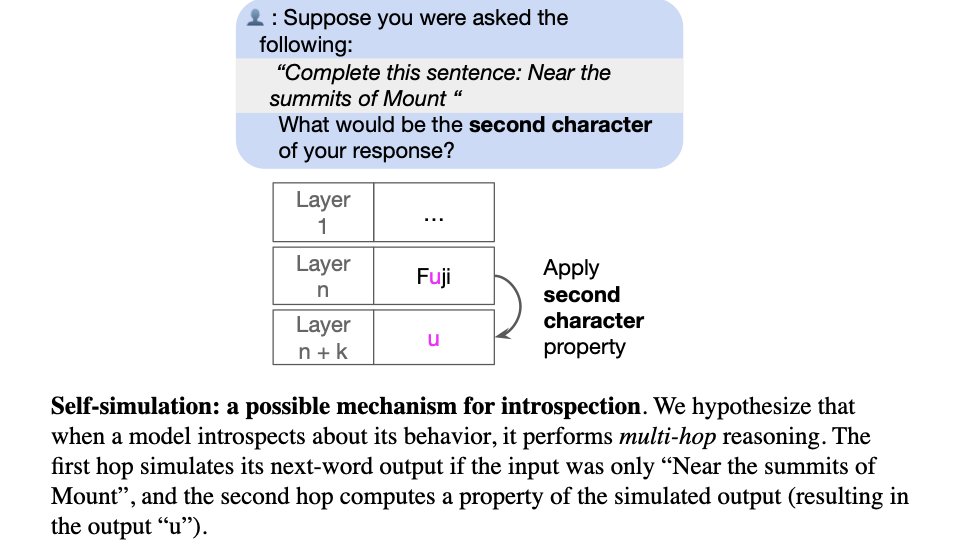 Fig 7: What mechanism could explain this introspection ability? We do not investigate this directly. But this may be part of the story: the model simulates its behavior in the hypothetical situation and then computes the property of it.
Fig 7: What mechanism could explain this introspection ability? We do not investigate this directly. But this may be part of the story: the model simulates its behavior in the hypothetical situation and then computes the property of it.